By Fiona Villamor on March, 10 2020

An Analance™ business case
With the technology today, electronic financial transactions offer a degree of convenience that simply cannot be provided by physical institutions. It’s a matter of being able to transfer money, make payments, and complete similar transactions—all without having to go to a bank or wait in line.
While this brings immediacy to financial transactions, sometimes this convenience comes with a risk. The complicated nature of mobile money has the potential to compromise security. For fraud management and compliance with anti-money laundering regulations, financial institutions should have measures in place to anticipate fraudulent transactions and mitigate risk.
Related: 4 ways the banking industry can benefit from Predictive Analytics
One way to combat financial fraud is to get foresight into why and when it might happen. Using predictive analytics, a machine learning model can identify the factors that contribute to fraud and produce accurate forecasts. This way, early intervention is possible, and the risks of fraud can be managed and reduced appropriately.

Mitigating financial fraud: A predictive analytics use case
To illustrate how predictive analytics helps prevent fraud, we used Analance to build a machine learning model that forecasts the probability of fraudulent transactions.
Since getting access to real financial transaction data is difficult due to its sensitive nature, we adopted an approach based on a Multi-Agent Based Simulation (MABS) for the generation of synthetic transaction data. We used this dataset to identify variables or predictors that significantly contribute to financial fraud.
Then, we trained the classification models in Analance and validated the results of all the algorithms in an ensemble mode to identify the best performing model for this case. The Random Forest Classification algorithm was the optimum model and was used to identify transactions that were most likely to be fraudulent.
Preparing the data
The synthetic dataset is a sample of real mobile money transactions that occurred over a period of a month. It had a total of 6,362,620 observations. We sourced this data through Analance’s SQL Server connector, which allows for real time/live data to be made available inside the platform.
- Data source – Mobile money transactions dataset
- Connector – Analance SQL Server
The dataset had 9 different predictor variables that were considered, including transaction amount, old balance and new balance of both sender and receiver, and transaction type. All variables available were studied to understand distributions.
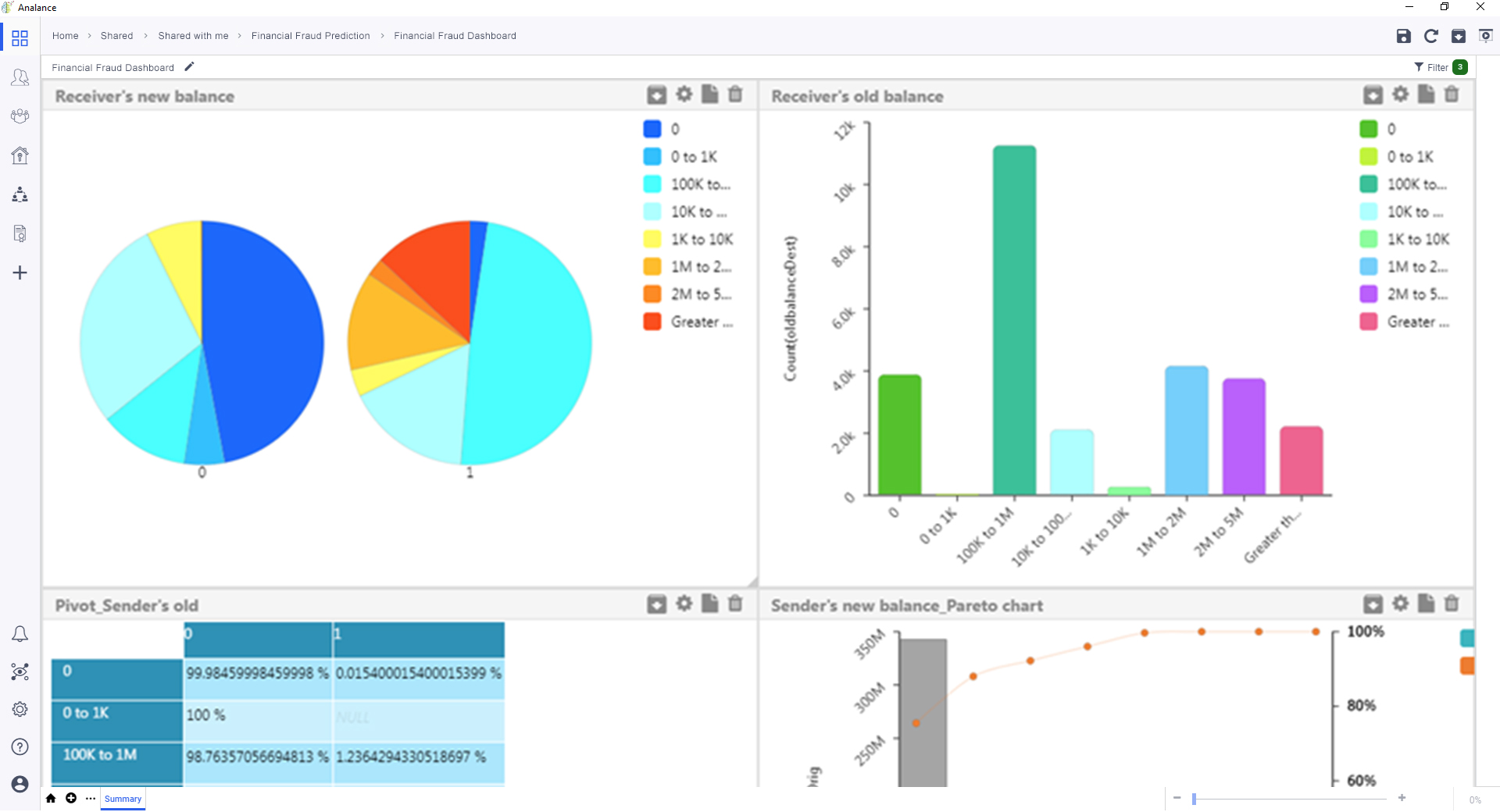
A univariate analysis was conducted on all variables in the dataset.
From this analysis, we found that under type of transaction, only Cash-out and Transfer types have fraud cases, hence we created a subset containing only the two categories. Additionally, we found that the percentage of fraud cases is <1%, so we down sampled the dataset to balance it out and better train the model. The new dataset consisted of 2,770,509 records.
Must-Read: Quality data = Quality results: Why Data Quality Management matters
After which, a Bivariate Analysis (Chi-Squared) was performed for all predictor-outcome combinations. This helped in restricting the analysis to only those predictors that majorly influence financial fraud.
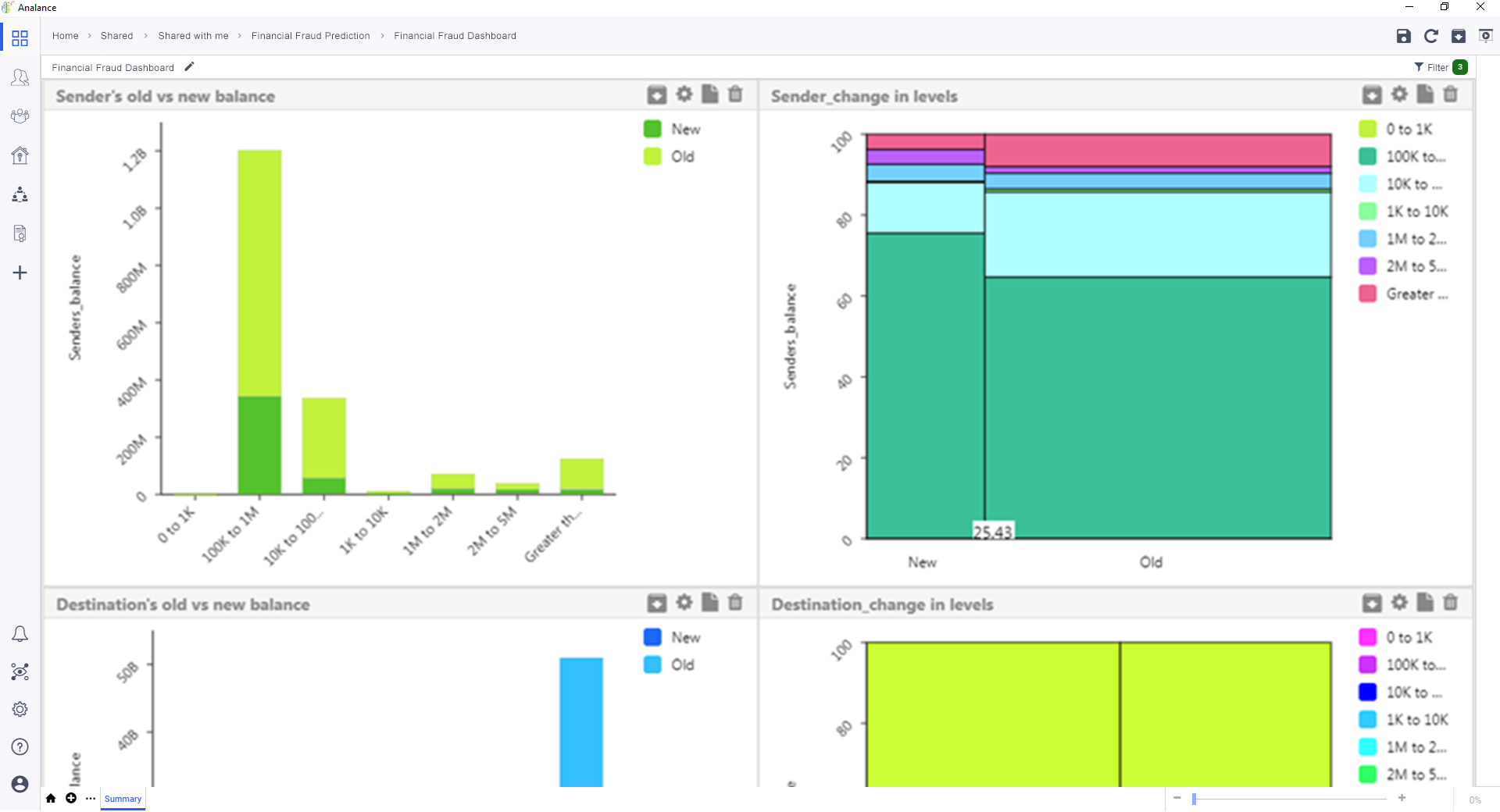
Conducting a bivariate analysis to explore the relationship between two variables.
From the analysis performed, the highest risk of financial fraud was found for:
- Transactions from origin accounts that suddenly dip to zero balance from an initial balance of 1M (77%).
- Transactions to destination accounts that show a sudden spike in balance from an initial balance between 0 and 100,000 (73%).
- Transactions to destination accounts with zero balance, despite receiving 1,000 to greater than 5M (50%).
- Transactions that range from 100,000 to 1M, and when both the sender’s new balance and receiver’s old balance is zero (46%).
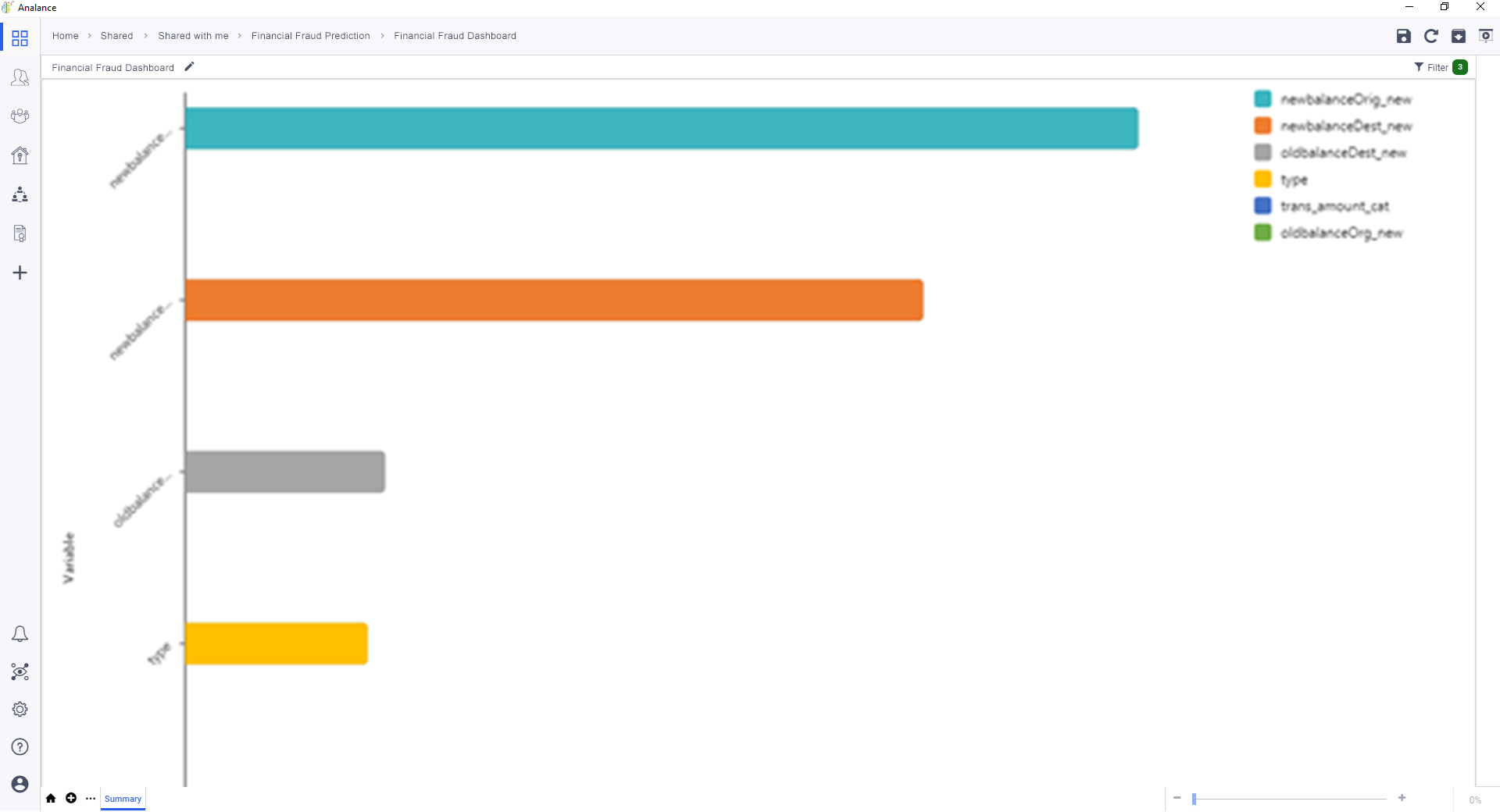
The variables chosen for modelling plus their significance in the outcomes.
Running the forecast
Once the data was prepared, the next step was to forecast the key metric chosen for the prediction. Analance has 41 prebuilt machine learning algorithms, with 8 for classification. We ran the classification model with all the available algorithms in an ensemble mode and analyzed the results to identify the best performing model for predicting financial fraud.
Compared to the other classification models, the Two-Class Adaptive Boosting algorithm had the highest Accuracy (0.96), optimum Recall (0.84) and Specificity value (0.97), and F1 score (0.87).
This means that the model accurately predicts 96% of the data. Given the Recall and Specificity values, it is able to predict 84% of fraudulent transactions and 97% of non-fraudulent transactions correctly. Lastly, based on the F1 score, the model predicts 87% of fraudulent transaction correctly, considering both false positives and false negatives.

Leveraging Machine Learning to manage financial fraud
With visibility into the variables that are likely to characterize fraudulent transactions, financial organizations can not only detect fraud but anticipate its occurrence.
This allows for early intervention to mitigate financial losses, avoid damage to company reputation and customer experience, and even keep company morale in check. For example, financial organizations can set up auto alerts for suspicious activity, launch educational campaigns for customers and users, and facilitate consistent monitoring to reduce risk.
See how fraud analytics and other banking solutions are built on Analance. Request a demo for our end-to-end enterprise data science platform today.
ABOUT THE AUTHOR

Fiona Villamor
Fiona Villamor is the lead writer for Ducen IT, a trusted technology solutions provider. In the past 8 years, she has written about big data, advanced analytics, and other transformative technologies and is constantly on the lookout for great stories to tell about the space.








